What is MongoDB?
MongoDB is a document database with the scalability and flexibility that you want with the querying and indexing that you need.
Stores data in flexible, JSON-like documents.
Document => Collection => Database
ref: what-is-mongodb).
Data Type
BSON vs JSON
BSON [bee · sahn]), short for Binary JSON, is a binary-encoded serialization of JSON-like documents.
继承自 JSON,具备 JSON 的通用性与 schema-less(例如与 Protocol Buffers 比较);
扩展了 JSON 的数据类型,提供了 JSON 没有的一些数据类型,例如: Date 和 BinData(byte array,有了这种类型以后就不需要像 JSON 一样需要先 base64 编码再存储,减少了计算和存储的开销);
BSON 的存储结构相比较 JSON 有更快的遍历速度;
BSON 的存储有数据类型的支持,字段更新的时候更快更方便。JSON 的存储由于没有数据类型的支持,字段的更新需要移动文档的内容,操作代价大。
BSON Spec ref:bsonspec)
头部存有数据结构的长度,有数据类型的支持,遍历起来快,不用像 JSON 一样进行各种复杂的数据结构匹配。
1 | {"hello": "world"} |
BSON Types
BSON is a binary serialization format used to store documents and make remote procedure calls in MongoDB.
ref:https://docs.mongodb.com/v2.6/reference/bson-types/
| Type | Number | Notes |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary Data | 5 | |
| Undefined | 6 | deprecated |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 12 | |
| JavaScript | 13 | |
| Symbol | 14 | deprecated |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
Comparison and Sort Order
不同数据类型之间的比较,类型之间有固定的比较优先级;
某些类型具有相同的优先级,比如:Numbers (ints, longs, doubles),比较之前先进行类型转换;
non-existent field 与 empty field 等价,即
{}与{a: null}等价;Array 类型之间的比较排序,根据比较排序的类型选择 Array 中最小值(<,ASC)或最大值(>,DESC) 来比较;只有一个元素的 Array 与非 Array 的元素比较排序时,则直接使用数组中的唯一元素进行比较;Empty Array 将视为小于 Null 或者 缺少字段;
String 类型使用的是 UTF-8存储,由不同编程语言的 driver 来负责序列化和反序列化 BSON。另外,由于
sort()函数内部使用 C++ strcmp api,在多语言环境中排序会有问题。MongoDB v3.4 引入collation) 参数。
ObjectId
Document 需要 _id 字段作为 primary key,Insert document 时如果没有手动指定的话,该字段由 Driver 或者 MongoDB Server 来负责自动生成。
MMAPv1 Storage Engine
ref:https://docs.mongodb.com/manual/core/mmapv1/
https://github.com/mongodb/mongo/tree/master/src/mongo/db/storage/mmap_v1
MMAPv1 是 MongoDB v3.2 之前的默认存储引擎,基于内存映射文件(memory mapped files),具有优秀的 Insert,read and in-place update 性能。v3.2 之后默认使用的是 WiredTiger 引擎。
MMAPv1 具有一下一些特点:
Journal,MongoDB 会先写 journal file(write-ahead redo logs),然后才是 data file,默认情况下 journal file 落地的时间是最大是 100ms,data file 落地的时间是最大是 60s(这是一个理论最大时间,实际上 OS 自身也有一个 flush 的落地操作)。这样当 MongoDB 发生故障的时候可以从 Journal 中恢复数据。
Document 连续地存储在磁盘中,当 Document 由于更新导致需要更多的存储空间时,需要重新分配空间并移动 Document 及更新相应的 Index。这会导致效率低下和存储碎片。
padding 模式, paddingFactor 存储空间冗余系数,1.0 表示没有冗余,1.5 表示 50% 的冗余,通常在 1.0 ~4.0 之间。这是 MongoDB 根据文档的频繁变化来调整的,我们无法控制,但是在 compact 的时候可以指定这个参数以控制压缩后的 Document 占用的实际空间:https://docs.mongodb.com/manual/reference/command/compact/#compact-paddingfactor。
usePowerOf2Sizes 模式( db.collection.stats()),从 MongoDB v2.6 开始作为默认的存储分配方式:https://docs.mongodb.com/v2.6/reference/command/collMod/#usePowerOf2Sizes,按照 2 的 N 次方进行存储空间分配,最小分配 32 bytes,即 32,64,128,256…16777216。MongoDB v3.0 之前当 Document 的空间分配超过 4M 以后就会按照四舍五入的方式分配最接近的 N megabyte。v3.0 开始是达到 2M 以后按照 2M 为最小单位进行增长分配:https://docs.mongodb.com/manual/core/mmapv1/#power-of-2-sized-allocations。
nopadding 模式,MongoDB v3.0 之后新增的一种分配方式,顾名思义最适合 insert-only 或者 update 不改变 Document size 的场景。
Free Memory 会尽可能(100%)被用来做 Cache 以提高性能。
Database Level Concurrency,数据库级别的锁。
数据库层级分配存储文件,不会自动回收分配出去的空间。
WiredTiger 存储引擎相比较 MMAPv1:
Document Level Concurrency,文档那个级别的锁。
Snapshot and Checkpoint,故障恢复支持 Snapshot 和 Journal 的方式。
Collection 层级分配存储文件,并及时回收空间,优化压缩且可配置压缩算法。
v3.2 以后可以配置最大占用内存空间。
Data File Structure
MongoDB 的文件分为 3 种,分别是
Journal File,日志文件,存放在 MongoDB 数据目录下的 journal 子目录下;
Namespace File,命名空间文件,后缀名为 『.ns』 的文件;
Data File,数据文件,存放 Document 和 Index,以 Collection Name 作为文件名前缀的文件。
Journal File
ref:https://docs.mongodb.com/v2.6/core/journaling/
存储在单独的 『journal』子目录下面,以 『j._』 作为文件名前缀。MongoDB 启动的时候会默认创建 3 个大小为 1 G 的空 journal file(append-only) 备用,当一个 journal file 中操作全部落地以后,MongoDB 便会删除该 journal file,除非有持续海量的数据写入,否也一般只会有 2 ,3 个 journal file。正常的关闭 MongoDB 会删除 journal file。将 Journal File 和 Data File 放在不同的 FileSystem 上可以加速频繁顺序写的性能。
调整 MongoDB 默认文件的大小,可以将 Journal File 的默认大小从 1 G 改为 128M。
Namespace File
ref:https://docs.mongodb.com/v2.6/reference/limits/#namespaces
MongoDB 每个 database 中都会包含一个后缀名为 『.ns』 的文件,用于存储 namespce 信息,实现上是一个 Hash Table 可以快速地定位某个 namespce 在 Data File 中位置。namespace 长度最大为 120 bytes(包括 『.』 分隔符在内不超过 120 个字符)。namaspace 在对应的数据结构大小为 624 bytes,默认一个 namaspce file 的大小为 16 M,也就是说可以支持 16M/624=26715 个 namespace。最大可通过参数配置为 2 G 大小。
Namespace 的数据结构如下所示:
1 | Node { |
hash: namespace 的 hash 值,使用的线性探测方式。
key:namaspce ,是一个长度为 120 bytes 的字符数组。
value:namespace 的详情,包括在 Data File 中起止位置(第一个 Extent 以及最后一个 Extent 的位置)及其他信息。
Data File
ref:https://docs.mongodb.com/v2.6/faq/storage/#preallocated-data-files
MongoDB 的 Data 和 Index 都存放在 Data File 中。为了防止文件系统碎片化, MongoDB 会以特定的 size 预先分配 Data File,命名从 0 开始:<database_name>.0, <database_name>.1…<database_name>.N, 第一个文件为 64M,第二个位 128M,直到 2G,之后都以 2G 大小来分配,也就是 MongDB 的 Data File 单个最大为 2G。
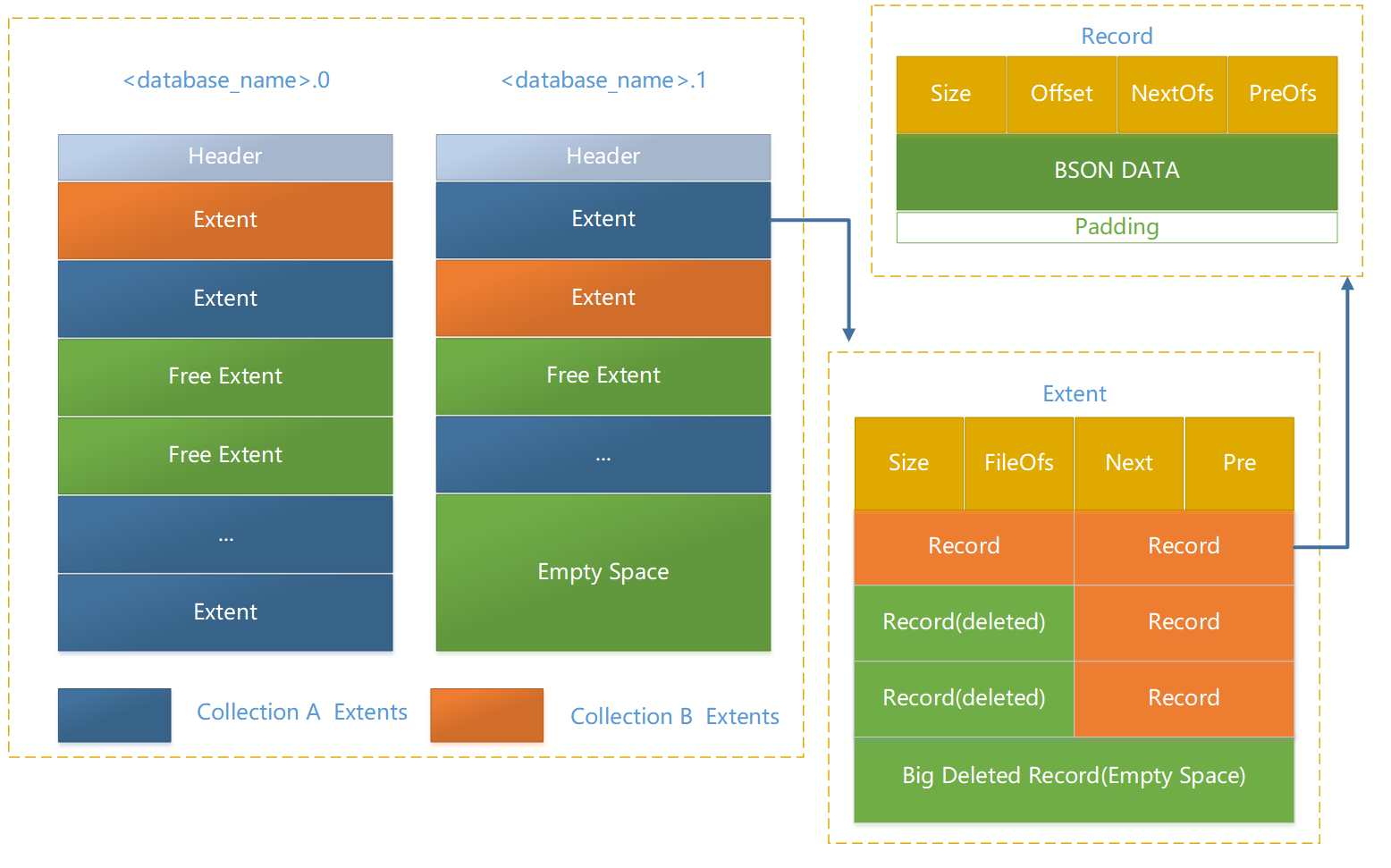
Data File 结构如上图所示:
一个 Data File 由多个 Extent 组成,一个 Extent 由多个 Record 组成,Record 中存储 MongoDB Document。Extent 和 Record 都被实现成双向链表。
一个 Extent 只会包含一个 Collection 的 Data 或者 Index,但是同一个 Extent 不会既有 Data 又有 Index。
一个 Collection 由多个 Extent 组成,这些 Extent 可以分布在多个 Data File 中。
Document 删除或移动(Not in-place update)后留下的未被使用的 Record 会被标记为 『Deleted Record』 而可以重新分配出去,但不会主动回收。『Deleted Record』在实现上会按照不同的 Size 组织成链表,加速重新分配过程。删除 Document 释放出来的 Extent 会被放到 Data File 的 Extent Free List 中。
关于 db.stats() 的几个 Size 的区别与联系:
dataSize: Records Total Size,Record 中包括 Header + BSON Data + Padding。
storageSize/indexSize: Extents Total Size,由于包含了 Delete Record 所以比 dataSize 大。
fileSize: 文件系统中文件的大小,包括了 Data Extent 、Index Extent 以及未被使用的空间,不会随着 DB 中 Document 的删除而减少。
Insert Document
检查 Namespace 对应的 『Deleted Record』 中是否有合适 Size 的 Record,如果有则直接复用这个空间,写入 Document(注:Extent 中空闲空间会被作为一个 Big Deleted Record 处理);
检查 Data File 的 Extent Free List 里面是否有合适大小的空闲 Extent 可用,如果有则使用空闲的 Extent,写入 Document;
否则就要创建新的 Extent,写入 Document 。如果 Data File 没有足够的空间创建 Extent 则创建新的 Data File。
Delete Document
删除 Document 释放出来的 Record 会作为 『Deleted Record』 复用,但不会主动回收。无法被复用的 Record 就会成为存储碎片,需要通过 Compact 操作来改善。
Update Document
In-place Update,否则就是 Delete + Insert 操作。释放出来的 Record 作为 『Deleted Record』 被复用。非 In-place Update 会导致存储碎片,可以通过调整 Document 空间分配模式来改善。
Query Document
没有索引的情况下就只能遍历整个 Collection ,直到找到对应的 Record(Document)。建立索引可以加速查询。