引言
在前面 Tornado 的分析文章中已经详细介绍了 HttpServer 接收处理客户端 Http 连接请求,并将请求委托给请求回调(即 HttpServer.request_callback 字段,由 HttpServer 的构造参数来完成初始化)处理的流程。基于 HttpServer 的支持,tornado.web 模块为我们提供了一个简单的 Web 框架,该框架支持路由请求到对应的(自定义/默认)请求处理器(RequestHandler)并自带一个简易的 HTML 模板引擎。在分析 tornado.web 模块的设计之前,先通过一张图来回顾一下 HttpServer 的处理流程,看看 web.tornado 提供的框架是如何获得支持的。
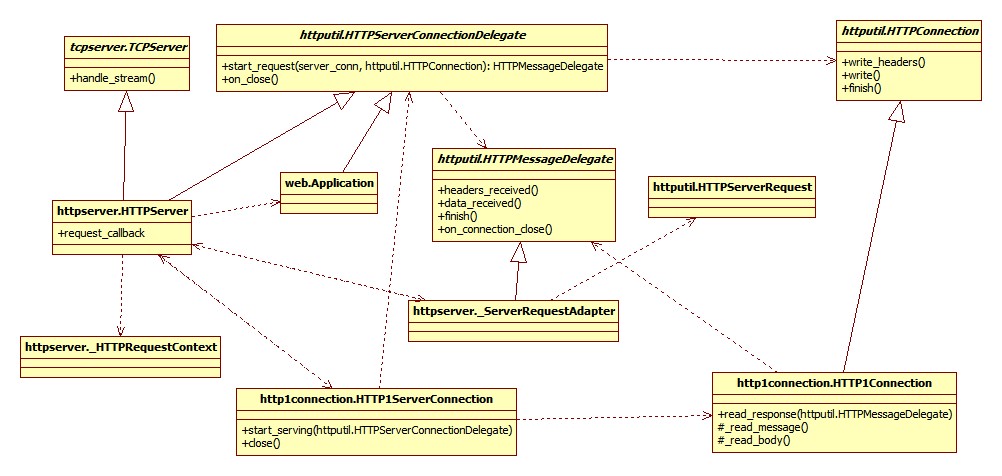
由上图可知:
httpsever.HttpServer继承自tcpserver.TCPServer并覆写了handle_stream(stream, address)方法。httpsever.HttpServer.handle_stream(stream, address)方法中将请求相关的 IOStream、地址和协议描述(http/https)保证成httpsever._HTTPRequestContext实例以构建http1connection.HTTP1ServerConnection实例,并调用Http1ServerConnection.start_serving方法启动请求处理。http1connection.HTTP1ServerConnection是一个支持 Http/1.x 的服务端抽象连接类型,也就是说能支持 Http/1.1 的长连接。在该连接实例服务周期中(实现在其_server_request_loop方法的 while 循环),其内部对于每一次 Http 请求会生成一个http1connection.HTTP1Connection实例。http1connection.Http1ServerConnection.start_serving(delegate:httputil.HTTPServerConnectionDelegate)方法要求接收一个httputil.HTTPServerConnectionDelegate实例,该实例的start_request(server_conn, request_conn:HTTP1Connection)方法返回一个httputil.HTTPMessageDelegate实例,该实例将与http1connection.HTTP1Connection实例配合处理 Http 请求的各个阶段。http1connection.HTTP1Connection是httputil.HTTPConnection的 Http/1.x 子类实现,是每次 Http 连接请求的抽象,提供了读取请求和数据和发送响应数据的接口。http1connection.HTTP1ServerConnection抽象了一个服务端的物理连接,http1connection.HTTP1Connection则抽象了每次 Http 请求的连接,这样一来前者就可以基于同一个物理连接处理多个 Http 请求,也就是支持了 Http 协议要求的长连接。
httpsever.HttpServer同时继承自httputil.HTTPServerConnectionDelegate,所以它能作为http1connection.HTTP1ServerConnection.start_serving()方法的参数为其提供实际的请求处理。对请求的处理工作httpsever.HttpServer实际上是委托给其内部的request_callback字段来进行,该字段在httpsever.HttpServer构造时初始化。在 Tornado v4.0 之前的版本中,request_callback是一个以httputil.HTTPServerRequest作为参数的回调对象,v4.0 之后引入httputil.HTTPMessageDelegate类型,随之request_callback改为支持httputil.HTTPMessageDelegate实例。为了向后兼容,httpsever.HttpServer.start_request方法返回一个httpserver._ServerRequestAdapter类型实例。httpserver._ServerRequestAdapter是一个对象适配器,它负责将之前的回调对象(适配者)适配到httputil.HTTPMessageDelegate类型。web.Application继承自httputil.HTTPServerConnectionDelegate,可作为请求连接处理回调对象传递给httpsever.HttpServer, 作为其request_callback字段负责处理请求。
到这里,httpsever.HttpServer 的整个处理过程基本回顾了一遍,后面处理将转到 web.Application ,开始进入 Tornado Web Framework 的处理流程。
Tornado Web Framwork
tornado.web 中实现的 Web 框架总的来看主要由 3 个部分(类)组成:
Application类型继承自httputil.HTTPServerConnectionDelegate,其实例可直接传递给 HttpServer 来处理客户端连接;RequestHandler类型是请求处理的基类型,其子类实例负责处理具体的请求,也就是 Tornado Web 框架分发请求的目标对象;_RequestDispatcher是一个模块内部类,继承自httputil.HTTPMessageDelegate。它把映射请求到具体RequestHandler实例的逻辑从Application分离出来,简化Application的实现。
也就是说实现上,Application 是一系列 RequestHandler 子类实例的集合,具体请求将根据主机和资源路径进行映射。映射关系则由 URLSpec 类型实例来描述,映射动作的执行(或者说请求分发)则由 _RequestDispatcher 来完成。
URLSpec
URLSpec 用于描述请求 URLs 与 handlers 的映射关系,别名是 url,即通过 web.url 也能引用该类型。URLSpec 的实现从构造方法就可窥见,与 URLs 的映射是通过正则表达式匹配来完成的。下面是其构造方法的签名:1
2
3
def __init__(self, pattern, handler, kwargs=None, name=None):
pass
pattern是用来匹配 URL 的正则表达式字符串。通过匹配得到的分组将作为 handler 实例 get/post 等等方法的参数调用;handler是将被实例化后用来处理器请求的RequestHandler子类,可以是一个 “module.ClassName” 格式的字符串;kwargs是handler实例化是传递给构造方法的参数;name是为给Application.reverse_url使用给handler取的名字。URLSpec提供方法reverse来配合 Application 工作,但不支持复杂的pattern,实现代码不复杂,感兴趣的可以看看。
RequestHandler
RequestHandler 是负责请求的处理(响应)的基类,是 Tornado 简单 Web 框架的重要组成部分。一般我们都会从它派生子类型来处理器具体的请求。RequestHandler 在 Tornado Web Framework 中的位置,有点类似Java Web 中的 Servlet 或者 ASP.NET 中的 HTTPHandler。
RequestHandler 中封装的功能细节比较多,基本上包含了响应的方方面面,这里我们主要关注其处理流程,具体的功能细节后续再分析。RequestHandler 请求处理流程的入口是方法 _execute,该方法会被 _RequestDispatcher 在 execute 方法中调用。_execute 方法代码不多,清晰表达了 RequestHandler 的处理流程。代码如下所示:
1 |
|
从上面的代码可看出 RequestHandler 中通过类字段 SUPPORTED_METHODS 来定义 Handler 支持的请求方法(Http method)列表,处理方法名字就是 Http Method 名称的小写字符(method = getattr(self, self.request.method.lower())),例如POST 请求对应 post 方法,GET 请求对应 get 方法。若 Handler 支持当前 Http Method,则进入处理流程:execute prepare method -> execute http method -> execute finish method。另外需要指出的一点是该方法被 gen.coroutine 装饰,没有返回值(或者说返回值 None ),但被一个完整的异常处理块包围而不会抛出任何异常,所以在 _RequestDispatcher 中可以不去关心其返回的 Future 实例何时完成,结果是什么,是否在异步执行时发生异常。
Application
Application 是一个 Web 应用的 Request Handler 集合。它支持按照虚拟主机/子域名/泛域名对 handler 进行映射,通过 add_handlers 方法可以指定 handler 对应的主机。Application 实例化时可以指定一些默认的 handler,这些 handler 适用于所有的主机地址(匹配主机地址的正则表达式被设置为 ".*$"),构造方法内也是通过调用 add_handlers 方法完成 handler 添加。下面是 add_handlers 的代码:
1 | def add_handlers(self, host_pattern, host_handlers): |
对上述代码可以做一些分析:
参数
host_pattern指定匹配主机地址的正则表达式字符串,host_handlers是一个list,其中的元素可以是URLSpec实例或者用于构造URLSpec实例的参数列表,若是后者需要动态创建URLSpec实例。self.handlers字段保存着所有的 handler 列表,其中的每个元素是一个 tuple 实例,tuple 实例的第一个元素是匹配主机的正则表达式实例,第二个元素是URLSpec实例列表,其中通配所有主机的元素优先级最低,默认添加到 handler 列表的尾部。对于命名的 handler 同时会被保存在
named_handlers字段中,以备reverse_url方法使用。
Application 作为 httputil.HTTPServerConnectionDelegate 的子类,其 start_request 方法将返回一个 _RequestDispatcher 实例来处理请求。在 Tornado v4.0.2 中,start_request 的方法签名与 httputil.HTTPServerConnectionDelegate 定义的不一致,貌似没有重构完成一样,不过后面版本中已经做了修正。1
2
3def start_request(self, connection):
# Modern HTTPServer interface
return _RequestDispatcher(self, connection)
Application 本身还有一些诸如启动 HttpSever,配置 debug 参数,HTML 模板解析支持等功能,这里我们仅分析梳理其处理请求的流程,这些功能就不再一一介绍。
_RequestDispatcher
_RequestDispatcher 是 httputil.HTTPMessageDelegate 的子类,负责将请求按照主机地址和资源路径分发到具体的 handler 实例。在 Tornado v4.0 之前,这部分功能属于 Application。这样的职责分离是程序不断重构的结果。
_RequestDispatcher 的代码比较简单,结合前面的介绍很容易看懂,这里就直接将分析内容写在代码注释中,不再单独赘述。
1 | class _RequestDispatcher(httputil.HTTPMessageDelegate): |